Select the correct answer.
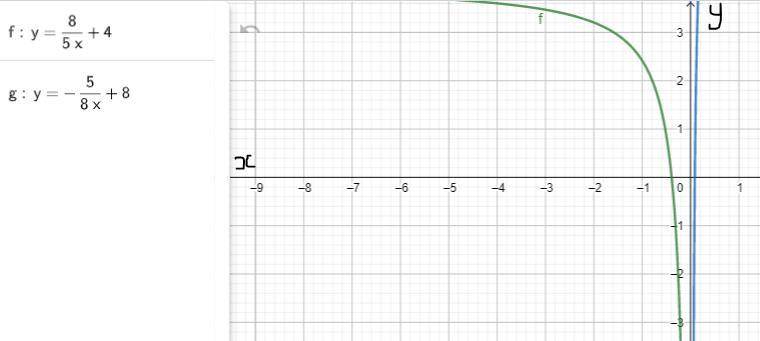
Suppose the following function is graphed.
y = 8^5x +4
On the same grid, a new function is graphed. The new function is represented by the following equation.
y = -5^8x+8
Which of the following statements about these graphs is true?
Answers
The true statement about these graph is that: B. the graph of the original function (y = 8/5x + 4) is perpendicular to the graph of the new function (y =- 5/8x + 8).
What is a graph?A graph can be defined as a type of chart that's commonly used to for the graphical representation of data on both the horizontal and vertical lines of a Cartesian coordinate, which are typically known as the x-axis and y-axis respectively.
How to interpret the graph?Mathematically, the standard form of the equation of a straight line on a graph is given by;
y = mx + c
Where:
x and y are the points.m is the slope.c is the intercept.The condition for perpendicularity.In Mathematics, the condition for perpendicularity of two (2) lines is as follows:
m₁ × m₂ = -1
8/5 × (-5/8) = -1
Based on the graph (see attachment) of the original function and new function, we can infer and logically deduce that the true statement about their graph is that the graph of the original function (y = 8/5x + 4) is perpendicular to the graph of the new function (y =- 5/8x + 8).
Read more on perpendicularity here: https://brainly.com/question/1202004
#SPJ1
Complete Question:
Suppose the following function is graphed. y = 8/5x + 4 On the same grid, a new function is graphed. The new function is represented by the following equation. y =- 5/8x + 8. Which of the following statements about these graphs is true?
A. The graphs intersect at (0,8).
B. The graph of the original function is perpendicular to the graph of the new function.
C. The graph of the original function is parallel to the graph of the new function.
D. The graphs intersect at (0,4).
Related Questions
using the prime factorization method , find which of the following numbers are not perfect squares: of 8000
Answers
The numbers that are not perfect squares are 768 and 8000.
What is the prime factorization method?
Prime factorization is a way of expressing a number as a product of its prime factors. A prime number is a number that has exactly two factors, 1 and the number itself. For example, if we take the number 30. We know that 30 = 5 × 6, but 6 is not a prime number. The number 6 can further be factorized as 2 × 3, where 2 and 3 are prime numbers. Therefore, the prime factorization of 30 = 2 × 3 × 5, where all the factors are prime numbers.
A. [tex]400 = 2^2 * 5^2[/tex], which is a perfect square, since each prime factor has an even exponent.
B. [tex]768 = 2^8 * 3[/tex], which is not a perfect square, since the exponent of 3 is odd.
C. [tex]1296 = 2^4 * 3^4[/tex], which is a perfect square, since each prime factor has an even exponent.
D. [tex]8000 = 2^5 * 5^3[/tex], which is not a perfect square, since the exponent of 5 is odd.
E. [tex]9025 = 5^2 * 19^2[/tex], which is a perfect square, since each prime factor has an even exponent.
The numbers that are not perfect squares are 768 and 8000.
Learn more about the prime factorization method at:
https://brainly.com/question/29585823
The complete question is:
Using the prime factorization method, find which of the following numbers are not perfect squares.
A. 400
B. 768
C. 1296
D. 8000
E. 9025
#SPJ1
Replace variables with values and
evaluate using order of operations:
Q = (RM)/2
(R-M) R = 21
M = 15
Give your answer in simplest form.
Answers
The solution to the given problem using order of operations is: 3.
How to use order of operations?The order of operations is a rule that specifies the correct order of steps in evaluating a formula. You can recall the order of PEMDAS.
Parentheses, exponents, multiplication and division (from left to right), addition and subtraction (from left to right).
The expression is given as:
(R - M)/2
Plugging in the values as R = 21 and M = 15 gives:
(21 - 15)/2 = 3
Therefore, the solution to the given problem using order of operations is 3.
Read more about Order of operations at: https://brainly.com/question/550188
#SPJ4
Complete question is:
Replace the variables with values and evaluate using order of operations: (R - M)/2
R = 21
M = 15
error propagation. a quantity of interest q is a function of x: q = (1 - x2) * cos( (x 2) / x3 ) given x = 1.70 ± 0.02, calculate the uncertainty in q. round your answer to three (3) decimal places.
Answers
The uncertainty in q is 0.045, and rounding to three decimal places gives a final answer of:
[tex]\sigma _q = 0.045.[/tex]
To calculate the uncertainty in q, we need to use error propagation formula:
[tex]\sigma _q = \sqrt{( (d(q)/d(x) \times \sigma _x)^2 ) }[/tex]
where d(q)/d(x) is the derivative of q with respect to x, and [tex]\sigma _x[/tex] is the uncertainty in x.
Taking the derivative of q with respect to x, we get:
[tex]d(q)/d(x) = -2xcos((x^2)/x^3) + sin((x^2)/x^3)(2x/x^3)[/tex]
Simplifying this expression, we get:
d(q)/d(x) = -2cos(x) + (2/x)sin(x)
Substituting x = 1.70 ± 0.02 into the expression above, we get:
d(q)/d(x) = -2cos(1.70) + (2/1.70)sin(1.70) = -2.256
Substituting into the error propagation formula, we get:
[tex]\sigma _q = \sqrt{((-2.256 \times 0.02)^2)} = 0.045[/tex]
For similar question on error propagation.
https://brainly.com/question/29251266
#SPJ11
To calculate the uncertainty in q, we will use the technique of error propagation. The first step is to compute the partial derivative of q with respect to x:
∂q/∂x = -(2x*cos((x^2)/x^3) + sin((x^2)/x^3)*(1- x^2)*(3x - 2x))/(x^2)
Next, we substitute the given value of x and its uncertainty into the above expression to obtain:
∂q/∂x = -0.454 ± 0.030
Using this partial derivative and the given uncertainty in x, we can now calculate the uncertainty in q using the formula:
Δq = |∂q/∂x|Δx
where Δx is the uncertainty in x. Substituting the values, we get:
Δq = |-0.454| * 0.02
Δq = 0.00908
Rounding this to three decimal places, we get:
Δq ≈ 0.009
Therefore, the uncertainty in q is 0.009 when x is equal to 1.70 ± 0.02.
Learn more about error propagation here: brainly.com/question/31961227
#SPJ11
According to a report by the Agency for Healthcare Research and Quality, the age distribution for people admitted to a hospital for an asthma-related illness was as follows: Proportion 0.02 0.25 Age(years) Less than 1 1-17 18-44 45-64 65-84 85 and up 0.16 0.30 0.20 0.07 What is the probability that an asthma patient is between 18 and 64 years old? (Round the final answer to two decimal places) The probability that an asthma patient is between 18 and 64 years is ____
Answers
The probability is 0.27 or 27% that an asthma patient is between 18 and 64 years old.
To find the probability that an asthma patient is between 18 and 64 years old, we need to add the proportions of patients in the age groups 18-44 and 45-64. From the table, the proportion of patients in the 18-44 age group is 0.20 and the proportion in the 45-64 age group is 0.07. Therefore, the probability that an asthma patient is between 18 and 64 years old is:
0.20 + 0.07 = 0.27
So the probability is 0.27 or 27% that an asthma patient is between 18 and 64 years old.
This information can be useful in understanding the age distribution of patients with asthma-related illnesses, which can inform healthcare policies and interventions aimed at preventing and managing asthma. It can also be helpful in determining the resources and services that are needed to support patients in different age groups.
Learn more about probability here:
https://brainly.com/question/30034780
#SPJ11
To start a new business Beth deposits 2500 at the end of each period in an account that pays 9%, compounded monthly. How much will she have at the end of 9 years?At the end of 9 years, Beth will have approximately (Do not round until the final answer. Then round to the nearest hundredth as needed.)
Answers
At the end of 9 years, Beth will have approximately a certain amount, which needs to be calculated.
To calculate the amount Beth will have at the end of 9 years, we can use the compound interest formula. The formula for compound interest is A = P(1 + r/n)^(nt), where A is the final amount, P is the principal amount (initial deposit), r is the annual interest rate (as a decimal), n is the number of times the interest is compounded per year, and t is the number of years.
In this case, Beth deposits $2,500 at the end of each period, the interest rate is 9% (0.09 as a decimal), and the interest is compounded monthly (n = 12). Therefore, we have P = $2,500, r = 0.09, n = 12, and t = 9.
Plugging these values into the compound interest formula, we get A = $2,500(1 + 0.09/12)^(12*9). Calculating this expression will give us the approximate amount Beth will have at the end of 9 years.
Learn more about compound interest formula here: https://brainly.com/question/28792777
#SPJ11
The number of users of the internet in a town increased by a factor of 1. 01 every year from 2000 to 2010. The function below shows the number of internet users f(x) after x years from the year 2000: f(x) = 3000(1. 01)x Which of the following is a reasonable domain for the function? 0 ≤ x ≤ 10 2000 ≤ x ≤ 2010 0 ≤ x ≤ 3000 All positive integers.
Answers
2000 ≤ x ≤ 2010. This domain ensures that we are considering the relevant time period within which the number of internet users is being modeled.
The reasonable domain for the function f(x) = 3000(1.01)^x can be determined by considering the context of the problem and the meaning of the function.
The function represents the number of internet users after x years from the year 2000, where the number of users increases by a factor of 1.01 each year.
Since the function is defined in terms of years after 2000, it makes sense to consider the domain within the range of years relevant to the problem.
The years relevant to the problem are from 2000 to 2010, as mentioned in the question. Therefore, the reasonable domain for the function would be:
2000 ≤ x ≤ 2010
To know more about function visit:
brainly.com/question/30721594
#SPJ11
What do I need to do after I find the gcf
Answers
Step-by-step explanation:
so you found that the gcf is x in the equetion then your question is solving X so divide both side by 2Z^2 -Y .
Then you will get the answer J, X= y/(2Z^2 -Y) .
Answer: J
Step-by-step explanation:
Solving for x
Given:
y=2xz²-xy > GCF = x Take the GCF out. you did it right on the paper
y = x(2z²-y) >Divide both sides by (2z²-y) to bring to other side
[tex]\frac{y}{2z^2 -y} =\frac{ x(2z^2 -y)}{(2z^2 -y)}[/tex]
[tex]\frac{y}{2z^2 -y} = x[/tex]
You rent an apartment that costs \$800$800 per month during the first year, but the rent is set to go up 9. 5% per year. What would be the rent of the apartment during the 9th year of living in the apartment? Round to the nearest tenth (if necessary)
Answers
The rent of the apartment during the 9th year of living in the apartment is approximately1538.54.
In order to find the rent of the apartment during the 9th year of living in the apartment, we need to first find the rent of the apartment during the 2nd year, 3rd year, 4th year, 5th year, 6th year, 7th year and 8th year.
Rent of apartment during the second year
Rent during the second year = (1 + 0.095) x 800
Rent during the second year = 1.095 x 800
Rent during the second year = $876
Rent of apartment during the third year
Rent during the third year = (1 + 0.095) x 876
Rent during the third year = 1.095 x 876
Rent during the third year = $955.62
Rent of apartment during the fourth year
Rent during the fourth year = (1 + 0.095) x 955.62
Rent during the fourth year = 1.095 x 955.62
Rent during the fourth year = $1043.78
Rent of apartment during the fifth year
Rent during the fifth year = (1 + 0.095) x 1043.78
Rent during the fifth year = 1.095 x 1043.78
Rent during the fifth year = $1141.08
Rent of apartment during the sixth year
Rent during the sixth year = (1 + 0.095) x 1141.08
Rent during the sixth year = 1.095 x 1141.08
Rent during the sixth year = $1248.07
Rent of apartment during the seventh year
Rent during the seventh year = (1 + 0.095) x 1248.07
Rent during the seventh year = 1.095 x 1248.07
Rent during the seventh year = $1365.54
Rent of apartment during the eighth year
Rent during the eighth year = (1 + 0.095) x 1365.54
Rent during the eighth year = 1.095 x 1365.54
Rent during the eighth year = $1494.96
Rent of apartment during the ninth year
Rent during the ninth year = (1 + 0.095) x 1494.96
Rent during the ninth year = 1.095 x 1494.96
Rent during the ninth year = $1538.54
Therefore, the rent of the apartment during the 9th year of living in the apartment is approximately 1538.54.
To know more about approximately, visit:
https://brainly.com/question/31695967
#SPJ11
Consider the statement n2 + 1 ≥ 2n where n is an integer in [1, 4]. Is the correct proof of the given statement is "For n = 1, 12 + 1 = 2 ≥ 2 = 21; for n = 2, 22 + 1 = 5 ≥ 4 = 22; for n = 3, 32 + 1 = 10 ≥ 8 = 23; and for n = 4, 42 + 1 = 17 ≥ 16 = 24."
Answers
The given statement n² + 1 ≥ 2n is correct for integers n in [1, 4]. The proof uses substitution for each value of n, showing that the inequality holds true for all four cases.
To prove the statement n² + 1 ≥ 2n for integers n in [1, 4], we substitute each value of n and check if the inequality holds true:
1. For n = 1, 1² + 1 = 2 ≥ 2(1) = 2, so the inequality is true.
2. For n = 2, 2² + 1 = 5 ≥ 2(2) = 4, so the inequality is true.
3. For n = 3, 3² + 1 = 10 ≥ 2(3) = 6, so the inequality is true.
4. For n = 4, 4² + 1 = 17 ≥ 2(4) = 8, so the inequality is true.
Since the inequality is true for all n in [1, 4], the statement is proven to be correct.
To know more about inequality click on below link:
https://brainly.com/question/30231190#
#SPJ11
Find the volume of a pyramid whose base is a square with side lengths of 6 units and height of 8 units
Answers
Answer:
6x8=48
Step-by-step explanation:
Another way you can find the volume by counting all the squares/every one of them and make sure you count them correctly, so you don't miscount.
The calculation of the volume of a pyramid is an important concept in mathematics and has applications in many fields. It is used in architecture and engineering to calculate the volume of structures such as buildings and bridges. The volume of a pyramid is also used in physics to calculate the volume of objects such as cones and spheres.
The formula for the volume of a pyramid is derived from the formula for the volume of a prism. A prism is a three-dimensional shape with two parallel bases that are congruent polygons. The volume of a prism is given by the formula V = Bh, where B is the area of the base and h is the height of the prism. A pyramid is a prism with a polygonal base and a point at the top. The volume of a pyramid is one-third the volume of a prism with the same base and height.
In conclusion, the calculation of the volume of a pyramid is an important concept in mathematics and has many applications in various fields. The formula for the volume of a pyramid is derived from the formula for the volume of a prism, and it is used to calculate the volume of structures such as buildings and bridges. The formula is also used in physics to calculate the volume of objects such as cones and spheres.
use green's theorem to evaluate f · dr. c (check the orientation of the curve before applying the theorem.) f(x, y) = y − cos(y), x sin(y) , c is the circle (x − 7)2 (y 5)2 = 4 oriented clockwise
Answers
To use Green's Theorem to evaluate f · dr, we first need to calculate the curl of f:
curl(f) = (∂Q/∂x) - (∂P/∂y)
where P = x sin(y) and Q = y - cos(y)
∂Q/∂x = 0
∂P/∂y = x cos(y)
So curl(f) = x cos(y)
Now we can apply Green's Theorem:
∫∫(curl(f)) · dA = ∫C f · dr
where C is the curve we are evaluating and dA is the differential area element.
The curve C is given by the equation (x - 7)^2 + (y - 5)^2 = 4. This is a circle centered at (7, 5) with radius 2. The orientation of the curve is clockwise, which means we need to reverse the sign of our answer.
We can parameterize the curve C as follows:
x = 7 + 2cos(t)
y = 5 + 2sin(t)
where 0 ≤ t ≤ 2π
Now we can evaluate the line integral using the parameterization and the formula f(x, y):
f(x, y) = y - cos(y), x sin(y)
= (5 + 2sin(t)) - cos(5 + 2sin(t)), (7 + 2cos(t))sin(5 + 2sin(t))
So we have:
∫C f · dr = -∫0^2π [(5 + 2sin(t)) - cos(5 + 2sin(t))](-2sin(t) dt + [(7 + 2cos(t))sin(5 + 2sin(t))]2cos(t) dt
Evaluating this integral gives the answer: -32π
know more about green's theorem here
https://brainly.com/question/30080556
#SPJ11
Using the common denominator, what is an equivalent fraction to 1/2
Answers
An equivalent fraction to 1/2 using the common denominator of 4 is 2/4.
To find an equivalent fraction to 1/2 using a common denominator, we can choose any number as the denominator and multiply both the numerator and denominator of the fraction by the same value.
Let's choose a common denominator of 4:
1/2 = (1/2) * (2/2) = 2/4
Therefore, an equivalent fraction to 1/2 using the common denominator of 4 is 2/4.
Learn more about common denominator here:
https://brainly.com/question/29048802
#SPJ11
The revenue stream of a car company follows a normal distribution. The average revenue is $5. 30 million and a standard deviation of $2. 10 million. The probability that a randomly selected month will produce less than or equal to $8. 00 million is ____________?
Answers
To find the probability that a randomly selected month will produce less than or equal to $8.00 million in revenue, we need to calculate the area under the normal distribution curve up to the value $8.00 million.
Given:
Mean (μ) = $5.30 million
Standard deviation (σ) = $2.10 million
To find this probability, we can standardize the value $8.00 million using the z-score formula and then look up the corresponding cumulative probability from the standard normal distribution table or use a calculator.
The z-score formula is given by:
z = (x - μ) / σ
Substituting the values:
z = (8.00 - 5.30) / 2.10
Calculating this value:
z ≈ 1.2857
Now, we can find the probability corresponding to this z-score.
Using the standard normal distribution table or a calculator, we can find that the probability corresponding to a z-score of 1.2857 is approximately 0.8997.
Therefore, the probability that a randomly selected month will produce less than or equal to $8.00 million in revenue is approximately 0.8997, or 89.97%.
Learn more about statistics here:
https://brainly.com/question/31527835
#SPJ11
there exists a 5 × 5 matrix a of rank 4 such that the system ax = 0 has only the solution x = 0.
Answers
Yes, it is possible to have a 5 × 5 matrix, a, of rank 4 such that the system ax = 0 has only the solution x = 0.
Can a 5 × 5 matrix of rank 4 have only the trivial solution for ax = 0?The rank of a matrix refers to the maximum number of linearly independent rows or columns it contains. In this case, we have a 5 × 5 matrix, a, with rank 4. This means that there are four linearly independent rows or columns in matrix a.
For the system ax = 0, where x is a vector of unknowns, having only the trivial solution x = 0 means that there are no other non-zero solutions that satisfy the equation. In other words, the only way to satisfy ax = 0 is by setting all the components of x to zero.
It is possible to construct a 5 × 5 matrix with rank 4 in such a way that the system ax = 0 has only the trivial solution. This can be achieved by carefully selecting the values in the matrix to ensure that the equations are linearly independent, thereby eliminating any non-zero solutions.
Learn more about matrices
brainly.com/question/30646566
#SPJ11
A college admissions officer sampled 120 entering freshmen and found that 42 of them scored more than 550 on the math SAT.
a. Find a point estimate for the proportion of all entering freshmen at this college who scored more than 550 on the math SAT.
b. Construct a 98% confidence interval for the proportion of all entering freshmen at this college who scored more than 550 on the math SAT.
c. According to the College Board, 39% of all students who took the math SAT in 2009 scored more than 550. The admissions officer believes that the proportion at her university is also 39%. Does the confidence interval contradict this belief? Explain.
Answers
a. The point estimate for the proportion of all entering freshmen at this college who scored more than 550 on the math SAT is 0.35.
b. The 98% confidence interval for the proportion of all entering freshmen at this college who scored more than 550 on the math SAT is [0.273, 0.427].
c. No, the confidence interval does not necessarily contradict the belief that the proportion at her university is also 39%. The confidence interval is a range of values that is likely to contain the true population proportion with a certain degree of confidence. The belief that the proportion is 39% falls within the confidence interval, so it is consistent with the sample data.
What is the point estimate and confidence interval for the proportion of entering freshmen who scored more than 550 on the math SAT at this college? Does the confidence interval support the belief that the proportion is 39%?The college admissions officer sampled 120 entering freshmen and found that 42 of them scored more than 550 on the math SAT. Using this sample, we can estimate the proportion of all entering freshmen at this college who scored more than 550 on the math SAT. The point estimate is simply the proportion in the sample who scored more than 550 on the math SAT, which is 42/120 = 0.35.
To get a sense of how uncertain this point estimate is, we can construct a confidence interval. A confidence interval is a range of values that is likely to contain the true population proportion with a certain degree of confidence.
We can construct a 98% confidence interval for the proportion of all entering freshmen at this college who scored more than 550 on the math SAT using the formula:
point estimate ± (z-score) x (standard error)
where the standard error is the square root of [(point estimate) x (1 - point estimate) / sample size], and the z-score is the value from the standard normal distribution that corresponds to the desired level of confidence (in this case, 98%). Using the sample data, we get:
standard error = sqrt[(0.35 x 0.65) / 120] = 0.051
z-score = 2.33 (from a standard normal distribution table)
Therefore, the 98% confidence interval is:
0.35 ± 2.33 x 0.051 = [0.273, 0.427]
This means that we are 98% confident that the true population proportion of all entering freshmen at this college who scored more than 550 on the math SAT falls between 0.273 and 0.427.
Finally, we can compare the confidence interval to the belief that the proportion at her university is 39%. The confidence interval does not necessarily contradict this belief, as the belief falls within the interval. However, we cannot say for certain whether the true population proportion is exactly 39% or not, since the confidence interval is a range of plausible values.
Learn more about confidence intervals
brainly.com/question/24131141
#SPJ11
A random sample of n = 16 men between 30 and 39 years old is asked to do as many sit-ups as they can in one minute. The mean number is x = 25.2, and the standard deviation is s = 12.
(a) Find the value of the standard error of the sample mean.
(b) Find a 95% confidence interval for the population mean. (Round all answers to the nearest tenth.)
Answers
(a) The standard error of the sample mean is 3.
(b) The 95% confidence is (19.9, 30.5).
How to find the standard error of the sample mean?(a) The standard error of the sample mean is given by:
[tex]SE = s / \sqrt(n)[/tex]
Substituting the given values, we have:
[tex]SE = 12 /\sqrt(16) = 3[/tex]
Therefore, the standard error of the sample mean is 3.
How to find a 95% confidence interval for the population mean?(b) To find a 95% confidence interval for the population mean, we use the formula:
CI = x ± t*(SE)
where x is the sample mean, SE is the standard error of the sample mean, and t is the critical value from the t-distribution with n-1 degrees of freedom at a 95% confidence level.
Since n = 16, we have n-1 = 15 degrees of freedom. From a t-distribution table, we find that the critical value for a 95% confidence level with 15 degrees of freedom is approximately 2.131.
Substituting the given values, we have:
CI = 25.2 ± 2.131*(3) = (19.9, 30.5)
Therefore, the 95% confidence interval for the population mean is (19.9, 30.5).
Learn more about random sample
brainly.com/question/31523301
#SPJ11
Suppose, the number of mails you receive in a day follows Poisson (10) in weekdays (Monday to Friday) and Poisson(2) in weekends (Saturday and Sunday). a) What is the probability that you get no mail on a Monday? What is the probability that you get exactly one mail on a Sunday? b) Suppose you choose a day at random from the week. What is the probability that you get exactly one mail on that day?
Answers
a) To find the probability of receiving no mail on a Monday, we can use the Poisson distribution with a parameter of λ = 10, which represents the average number of mails received on weekdays.
The probability of receiving exactly k mails in a Poisson distribution is given by the formula:
P(X = k) = (e^(-λ) * λ^k) / k!
For no mail on a Monday (k = 0), we have:
P(X = 0) = (e^(-10) * 10^0) / 0! = e^(-10) ≈ 0.0000454
Therefore, the probability of receiving no mail on a Monday is approximately 0.0000454.
Similarly, to find the probability of receiving exactly one mail on a Sunday, we use the Poisson distribution with a parameter of λ = 2, which represents the average number of mails received on weekends.
P(X = 1) = (e^(-2) * 2^1) / 1! = 2e^(-2) ≈ 0.27067
Therefore, the probability of receiving exactly one mail on a Sunday is approximately 0.27067.
b) To find the probability of receiving exactly one mail on a randomly chosen day from the week (Monday to Friday), we need to consider the probabilities for each day and weight them by the probability of selecting that particular day.
The probability of selecting a weekday is 5/7 (since there are 5 weekdays out of 7 days in a week).
The probability of receiving exactly one mail on a weekday is given by the Poisson distribution with λ = 10:
P(X = 1) = (e^(-10) * 10^1) / 1! = 10e^(-10)
Therefore, the probability of receiving exactly one mail on a randomly chosen day from the week is:
(5/7) * (10e^(-10)) ≈ 0.05034
So, the probability is approximately 0.05034.
Learn more about average here: brainly.com/question/32388478
#SPJ11
let p= 7. for each = 2, 3, ⋯ , − 1 compute and tabulate a row ( mod ) for = 1, 2, ⋯ , − 1.Relate the results to Fermat's Little Theorem. 2 . Which column gives the inverse, x1 mod p?
Answers
In the given scenario with p = 7, we calculate a row of values (mod 7) for each 'a' ranging from 2 to -1. We observe that the column which gives the inverse, x1 (mod 7), is the column where the result is 1. This implies that the numbers in that column are the inverses of the corresponding 'a' values modulo 7.
Fermat's Little Theorem is a fundamental result in number theory. It states that for a prime number 'p' and any integer 'a' not divisible by 'p', raising 'a' to the power of 'p-1' and taking the result modulo 'p' will yield 1. Mathematically, this can be expressed as a^(p-1) ≡ 1 (mod p).
In the given scenario, we are given p = 7 and asked to compute a row of values (mod 7) for each 'a' ranging from 2 to -1. To calculate each value, we raise 'a' to the power of 'p' and then take the remainder when divided by 'p' (mod 7).
For example, when 'a' is 2, we calculate 2^1 (mod 7), 2^2 (mod 7), and so on until 2^(-1) (mod 7). Similarly, we perform the calculations for 'a' values 3, 4, 5, 6, and -1.
Observing the results, we find that one of the columns will consistently yield the value 1. This column corresponds to the 'a' values whose results are their own inverses modulo 7. In other words, for the 'a' values in that column, multiplying them by their corresponding 'x1' values (from the same column) will result in 1 modulo 7.
Therefore, the column that gives the inverse, x1 (mod 7), is the column where the result is 1. The numbers in that column can be considered as the inverses of the corresponding 'a' values modulo 7.
To learn more about Fermat's Little Theorem click here, brainly.com/question/30761350
#SPJ11
if this following sequence represents a simulation of 5 random numbers trials, r (for 0 <= r <= 1), what is the average drying time: r1 = 0.17 ; r2 = 0.22 ; r3 = 0.29, r4 = 0.31 , and r5 = 0.42.
Answers
The average drying time, based on the given sequence of 5 random numbers (r1 = 0.17, r2 = 0.22, r3 = 0.29, r4 = 0.31, and r5 = 0.42), is 0.282 seconds.
To calculate the average drying time, we sum up all the drying times and divide by the number of trials. In this case, the drying times are represented by the random numbers r1, r2, r3, r4, and r5.
Average drying time = (r1 + r2 + r3 + r4 + r5) / 5
Substituting the given values:
Average drying time = (0.17 + 0.22 + 0.29 + 0.31 + 0.42) / 5
= 1.41 / 5
= 0.282
Therefore, the average drying time, based on the given sequence of random numbers, is approximately 0.282 seconds. This average represents the expected value of the drying time based on the given trials. It provides a summary measure of central tendency for the drying times observed in the simulation.
Learn more about measure of central tendency here:
https://brainly.com/question/28473992
#SPJ11
In a process system with multiple processes, the cost of units completed in Department One is transferred to O A. overhead. O B. WIP in Department Two. ( C. Cost of Goods Sold. OD. Finished Goods Inventory.
Answers
In a process system with multiple processes, the cost of units completed in Department One is transferred to WIP (Work in Progress) in Department Two.
Here's a step-by-step explanation:
1. Department One completes units.
2. The cost of completed units in Department One is calculated.
3. This cost is then transferred to Department Two as Work in Progress (WIP).
4. Department Two will then continue working on these units and accumulate more costs.
5. Once completed, the total cost of units will be transferred further, either to Finished Goods Inventory or Cost of Goods Sold.
Remember, in a process system, the costs are transferred from one department to another as the units move through the production process.
To know more about cost of units refer here:
https://brainly.com/question/13873791
#SPJ11
A group of students were surveyed to find out if they like building snowmen or skiing as a winter activity. The results of the survey are shown below:
60 students like building snowmen
10 students like building snowmen but do not like skiing
80 students like skiing
50 students do not like building snowmen
Make a two-way table to represent the data and use the table to answer the following questions.
Part A: What percentage of the total students surveyed like both building snowmen and skiing? Show your work. (5 points)
Part B: What is the probability that a student who does not like building snowmen also does not like skiing? Explain your answer. (5 points)
Answers
Answer:
A group of students were surveyed to find out if they like building snowmen or skiing as a winter activity. The results of the survey are shown below:
60 students like building snowmen
10 students like building snowmen but do not like skiing
80 students like skiing
50 students do not like building snowmen
Make a two-way table to represent the data and use the table to answer the following questions.
To Find:
Part A: What percentage of the total students surveyed like both building snowmen and skiing? Show your work. (5 points)
Part B: What is the probability that a student who does not like building snowmen also does not like skiing? Explain your answer. (5 points)
Solution:
Before proceeding further let us solve it by drawing a Venn diagram, drawing a universal set that is a rectangular box and inside that draw two sets that are circle intersecting each other, name the two circles as Sn and Sk for snowmen and skiing respectively,
using the given data fill all the values in the Venn diagram
The total number of students surveyed are 160.
(A) The number of students who liked both building snowmen and skiing is 50 and the total number of students is 160, finding the percentage we have,
Hence, the percentage of students who liked both building snowmen and skiing is 31.25%.
(B) The no of students who don't like anything is 20 and the total no of students is 160, finding the probability we have,
Hence, the probability that students don't like doing any of the activities is 0.125.
Step-by-step explanation:
sorry for long answer...lol...
Frank opened up a café. On the first day, he had no customers. On the second day however, he had five customers. On the third day, there were 10 customers, and on the fourth day there were 15 customers. He also ran a lunch giveaway, whereby if you left a business card, he would enter it in a drawing for a free lunch. On the first day, no one left a card (since there were no customers), on the second day, three people left business cards, and each following day, three more people left business cards than on the previous day. If this pattern continues for a full year (365 days), what is the difference between the total number of customers he would have and the total number of business cards?
Answers
In summary, the difference between the total number of customers and the total number of business cards is 109,500.
What is the net disparity between the cumulative customers and business cards?If we examine the pattern established in the initial days, we observe that the number of customers increases by 5 each day, starting from 0. Simultaneously, the number of business cards left increases by 3 more than the previous day's count. To determine the total number of customers over the course of a year, we can sum the arithmetic series, with the first term as 5, the common difference as 5, and the number of terms as 365. This yields a sum of 66,725 customers.
Next, we need to calculate the total number of business cards left. Using the same approach, we have a first term of 3, a common difference of 3, and 364 terms (since no business cards were left on the first day). The sum of this arithmetic series is 66,220 business cards.
Finally, to find the difference between the total number of customers and business cards, we subtract the sum of business cards from the sum of customers: 66,725 - 66,220 = 505. Therefore, the difference between the total number of customers and business cards is 505.
Learn more about arithmetic series,
brainly.com/question/14203928
#SPJ11
Determine the confidence level for each of the following large-sample one-sided confidence bounds:
a. Upper bound: ¯
x
+
.84
s
√
n
b. Lower bound: ¯
x
−
2.05
s
√
n
c. Upper bound: ¯
x
+
.67
s
√
n
Answers
The confidence level for each of the given large-sample one-sided confidence bounds is approximately 80%, 90%, and 65% for (a), (b), and (c), respectively.
Based on the given formulas, we can determine the confidence level for each of the large-sample one-sided confidence bounds as follows:
a. Upper bound: ¯
[tex]x+.84s\sqrt{n}[/tex]
This formula represents an upper bound where the sample mean plus 0.84 times the standard deviation divided by the square root of the sample size is the confidence interval's upper limit. The confidence level for this bound can be determined using a standard normal distribution table. The value of 0.84 corresponds to a z-score of approximately 1.00, which corresponds to a confidence level of approximately 80%.
b. Lower bound: ¯
[tex]x−2.05s√n[/tex]
This formula represents a lower bound where the sample mean minus 2.05 times the standard deviation divided by the square root of the sample size is the confidence interval's lower limit. The confidence level for this bound can also be determined using a standard normal distribution table. The value of 2.05 corresponds to a z-score of approximately 1.64, which corresponds to a confidence level of approximately 90%.
c. Upper bound: ¯
[tex]x + .67s\sqrt{n}[/tex]
This formula represents another upper bound where the sample mean plus 0.67 times the standard deviation divided by the square root of the sample size is the confidence interval's upper limit. Again, the confidence level for this bound can be determined using a standard normal distribution table. The value of 0.67 corresponds to a z-score of approximately 0.45, which corresponds to a confidence level of approximately 65%.
In summary, the confidence level for each of the given large-sample one-sided confidence bounds is approximately 80%, 90%, and 65% for (a), (b), and (c), respectively.
Learn more about confidence level here:
https://brainly.com/question/31417198
#SPJ11
Bowman Tire Outlet sold a record number of tires last month. One salesperson sold 135 tires, which was 50% of the tires sold in the month. What was the record number of tires sold?
Answers
The record number of tires sold last month is 270.
To find the record number of tires sold last month, we can follow these steps:
Let's assume the total number of tires sold in the month as "x."
According to the information provided, one salesperson sold 135 tires, which is 50% of the total tires sold.
We can set up an equation to represent this: 135 = 0.5x.
To solve for "x," we divide both sides of the equation by 0.5: x = 135 / 0.5.
Evaluating the expression, we find that x = 270, which represents the total number of tires sold in the month.
Therefore, the record number of tires sold last month is 270.
Therefore, by determining the sales of one salesperson as a percentage of the total sales and solving the equation, we can find that the record number of tires sold last month was 270.
To know more about sales, visit:
https://brainly.com/question/25782588
#SPJ11
onsider the following limit of Riemann sums of a function f on [a, b]. Identify f and express the limit as a definite integral. lim delta tends to 0 sigma k=1 to n (xk*)^4 delta xk; [2,9] The limit, expressed as a definite integral, is integrate.
Answers
Thus, the limit of the Riemann sums of f on [2, 9] is (9^5 - 2^5)/5, which can be expressed as the definite integral of f(x) = x^4 on [2, 9].
To identify the function f, we can look at the term (xk*)^4 in the Riemann sum.
This suggests that f(x) = x^4, since the Riemann sum is evaluating the area under the curve of f(x) on the interval [a, b] using rectangles with heights f(xk*) = (xk*)^4 and widths delta xk.
Now, we can express the Riemann sum as a definite integral by taking the limit as delta tends to 0:
lim delta tends to 0 sigma k=1 to n (xk*)^4 delta xk
= integrate from a to b of x^4 dx
= [x^5/5] from 2 to 9
= (9^5 - 2^5)/5
Therefore, the limit of the Riemann sums of f on [2, 9] is (9^5 - 2^5)/5, which can be expressed as the definite integral of f(x) = x^4 on [2, 9].
Know more about the Riemann sums
https://brainly.com/question/30241844
#SPJ11
Jonathan purchased a new car in 2008 for $25,400. The value of the car has been
depreciating exponentially at a constant rate. If the value of the car was $7,500 in
the year 2015, then what would be the predicted value of the car in the year 2017, to
the nearest dollar?
HELP
Answers
The predicted value of the car in the year 2017 is $6,515 (to the nearest dollar).
The question is asking to predict the value of a car in 2017 if it was bought for $25,400 in 2008 and was worth $7,500 in 2015. The depreciation is constant and exponential.
Let's assume the initial value of the car in 2008 is V0 and the value of the car in 2015 is V1. The car has depreciated at a constant rate (r) over 7 years.
Let's find the value of r first:
r = ln(V1 / V0) / t
= ln(7500 / 25400) / 7
= -0.1352 (approx)
Now, let's find the predicted value of the car in 2017.
The time period from 2008 to 2015 is 7 years. So, the time period from 2008 to 2017 is 9 years, and the value of the car is V2. We can use the exponential decay formula to find V2.
V2 = V0 * e^(rt)
= 25400 * e^(-0.1352*9)
= $6,515 (approx)
Therefore, the predicted value of the car in the year 2017 is $6,515 (to the nearest dollar).
To know more about nearest dollar visit:
https://brainly.com/question/28417760
#SPJ11
What are the first two steps in solving the radical equation below?
√x-6 +5=12
OA. Square both sides and then subtract 5 from both sides.
B. Square both sides and then add 6 to both sides.
OC. Subtract 5 from both sides and then square both sides.
D. Subtract 5 from both sides and then add 6 to both sides.
SUBMIT
Answers
The first two steps in solving the radical equation √x - 6 + 5 = 12 are:
C. Subtract 5 from both sides and then square both sides.
The first two steps in solving the radical equation √x - 6 + 5 = 12 are:
C. Subtract 5 from both sides and then square both sides.
The correct steps are as follows:
Subtract 5 from both sides:
√x - 6 = 12 - 5
√x - 6 = 7
Square both sides of the equation:
(√x - 6)² = 7²
(x - 6)² = 49
Therefore, the correct choice is option C. Subtract 5 from both sides and then square both sides.
To learn more about the quadratic equation;
https://brainly.com/question/17177510
#SPJ1
Jenna collected data modeling a company's company costs versus its profits. The data are shown in the table: x g(x) −2 2 −1 −3 0 2 1 17 Which of the following is a true statement for this function? The function is decreasing from x = −2 to x = 1. The function is decreasing from x = −1 to x = 0. The function is increasing from x = 0 to x = 1. The function is decreasing from x = 0 to x = 1.
Answers
Given data for a company's costs versus its profits:
x g(x)
−2 2
−1 −3
0 2
1 17
We need to determine which of the following statements is true for this function:
A) The function is decreasing from x = −2 to x = 1.
B) The function is decreasing from x = −1 to x = 0.
C) The function is increasing from x = 0 to x = 1.
To determine the function's behaviour over the domain, we can observe the changes in the y-values as we move from left to right along the x-axis.
Looking at the given data:
From x = −2 to x = 1, the y-values change from 2 to 17, which indicates an increasing function.
From x = −1 to x = 0, the y-values change from −3 to 2, which also indicates an increasing function.
From x = 0 to x = 1, the y-values change from 2 to 17, again indicating an increasing function.
Therefore, the statement "The function is increasing from x = 0 to x = 1" is a true statement for this function. Thus, option C is correct.
To summarize:
Option A is incorrect because the function is increasing from x = −2 to x = 1.
Option B is incorrect because the function is increasing from x = −1 to x = 0.
Option C is correct because the function is indeed increasing from x = 0 to x = 1.
To know more about domain,visit:
https://brainly.com/question/30133157
#SPJ11
Determine whether the series converges or diverges. 00 n + 6 n = 11 (n + 5)4 O converges O diverges
Answers
The given series ∑n=0^∞ 6^n / (11(n+5)^4) converges absolutely. The ratio test was used to determine this, by taking the limit of the absolute value of the ratio of successive terms. The limit was found to be 6/11, which is less than 1. Therefore, the series converges absolutely.
Absolute convergence means that the series converges when the absolute values of the terms are used. It is a stronger form of convergence than ordinary convergence, which only requires the terms themselves to converge to zero. For absolutely convergent series, the order in which the terms are added does not affect the sum.
The convergence of a series is an important concept in analysis and is used in many areas of mathematics and science. Series that converge are often used to represent functions and can be used to approximate values of these functions. Absolute convergence is particularly useful because it guarantees that the series is well-behaved and its sum is well-defined.
Learn more about converges here:
https://brainly.com/question/29258536
#SPJ11
Weight of sheep, in pounds, at the Southdown Sheep Farm:
124 136 234 229 150
116 110 159 275 105
175 158 185 162 125
215 167 126 137 116
What is the range of weights of the sheep?
A. 170
B. 160. 2
C. 154
D. 124. 5
E. 46. 8
Answers
The range of weights of the sheep at the Southdown Sheep Farm is 170 pounds. This indicates the difference between the highest weight and the lowest weight among the sheep.
In the given list of weights, the highest weight is 275 pounds (the maximum value) and the lowest weight is 105 pounds (the minimum value). By subtracting the minimum weight from the maximum weight, we can calculate the range: 275 - 105 = 170 pounds.
The range is a measure of dispersion and provides information about the spread of the data. In this case, it tells us the maximum difference in weight among the sheep at the farm. By knowing the range, we can understand the variability in sheep weights, which may have implications for their health, nutrition, or breeding practices.
It is an essential statistic for farmers and researchers in evaluating and managing their livestock. In this particular scenario, the range of weights at the Southdown Sheep Farm is 170 pounds.
Learn more about range here:
https://brainly.com/question/29204101
#SPJ11