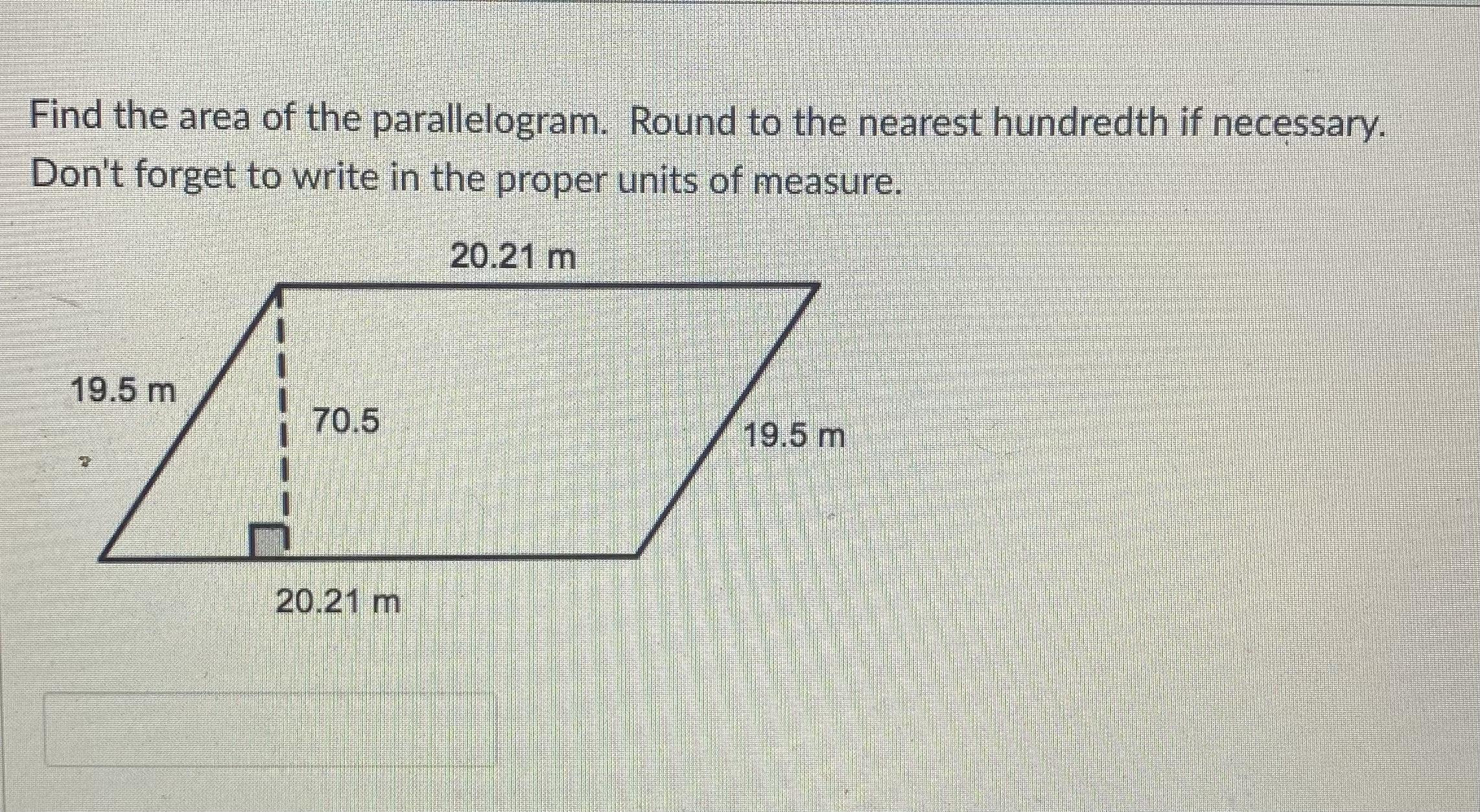
Find the area of the parallelogram. Round to the nearest hundredth if necessary.
Answers
Answer:
1424.81 square meters
Step-by-step explanation:
20.21 m * 70.5m = 1424.805 square meters
So then you round it to the nearest hundredth so then..
1424.81 square meters
Step-by-step explanation:
A of a parallelogram = Base ×height
= 20.21×70.5= 1424.805m
nearest hundreth = 1424.81 m
Related Questions
Jordan is constructing the bisector of What should Jordan do for the first step? Question 1 options: Place the point of the compass on point M and draw an arc, making sure the width is greater than ½ MN. Place the point of the compass on point M and draw an arc, making sure the width of the compass opening is less than ½ MN. Use the straightedge to extend in both directions. Use the straightedge to draw the line that passes through point M.
Answers
The given choices for the question are the following: Place the point of the compass on point M and draw an arc, making sure the width is greater than ½ MN. Place the point of the compass on point M and draw an arc, making sure the width of the compass opening is less than ½ MN.
Use the straightedge to extend in both directions. Use the straightedge to draw the line that passes through point M. The correct option to choose for the first step for Jordan to construct the bisector of angle LMN is Place the point of the compass on point M and draw an arc, making sure the width of the compass opening is less than ½ MN.
An angle bisector is a straight line that divides an angle into two equal parts. An angle bisector is a straight line that divides an angle into two equal parts. It is named by the angle's vertex and the two rays that form the angle. Suppose angle LMN is the angle that Jordan is constructing the bisector. Jordan should start by creating an angle bisector by doing the following:
Step 1: Jordan should Place the point of the compass on point M and draw an arc, making sure the width of the compass opening is less than ½ MN.
Step 2: Jordan should Place the point of the compass on point N and draw an arc of the same size as the previous arc.
Step 3: Jordan should draw a line connecting the point where the two arcs meet with the vertex of the angle.
Step 4: Jordan should add an arrowhead to the line to indicate that it is an angle bisector.
To know more about Arc visit :
https://brainly.com/question/31612770
#SPJ11
NEED HELP ASAP PLEASE!
Answers
The probability of selecting a black marble followed by a red marble with replacement is option A: 4.7%.
What is the probability?Based on the question, for one to calculate the probability of selecting a black marble followed by a red marble, we need to look at the two independent events which are:
selecting a black marble selecting a red marble.So, the probability of selecting a black marble on the first draw is:
2 black marbles out of a total of 16 marbles (6 red + 3 yellow + 2 black + 5 pink)
= 2/16 approximately 1/8.
Based on the fact that the marble is replaced, the probabilities for each draw will have to remain the same.
So, the probability of selecting a red marble on the second draw = 6 red marbles out of a total of 16 marbles
= 6/16
= 3/8.
To know the probability of both events occurring, we need to multiply the sole probabilities:
P(black marble and then red marble) = P(black marble) x P(red marble)
= (1/8) x (3/8)
= 3/64
So one can Convert the probability to a percentage, and it will be:
P(black marble and then red marble) = 0.047
= 4.7%
Learn more about probability from
https://brainly.com/question/24756209
#SPJ1
see text below
A bag contains 6 red, 3 yellow, 2 black, and 5 pink marbles. What is the probability of selecting a black marble followed by a red marble? The first one is replaced.
4.7%
12.5%
78.3%
75%
the null hypothesis for a binomial test states that p = 1/5. what is the z-score for x = 29 in a sample of n = 100
Answers
Thus, the z-score for x = 29 in a sample of n = 100 is -1.5. This means that the observed proportion of successes in the sample is 1.5 standard deviations below the expected proportion under the null hypothesis.
A binomial test is used to determine whether an observed proportion of successes in a sample is significantly different from a hypothesized proportion of successes.
The null hypothesis for this test states that the proportion of successes is equal to a specific value, in this case, p = 1/5.
To find the z-score for x = 29 in a sample of n = 100, we first need to calculate the expected proportion of successes under the null hypothesis. This is equal to p = 1/5 = 0.2.
Next, we calculate the standard deviation of the sampling distribution of the sample proportion, which is equal to sqrt(p*(1-p)/n) = sqrt(0.2*(1-0.2)/100) = 0.04.
The z-score is then calculated as (x - np) / √(np(1-p)), where x is the number of successes in the sample, n is the sample size, and p is the hypothesized proportion of successes.
Plugging in the values, we get:
z = (29 - 100*0.2) / sqrt(100*0.2*0.8)
z = -1.5
The z-score for x = 29 in a sample of n = 100 is -1.5.
We would compare this z-score to a critical value based on the desired level of significance to determine whether to reject or fail to reject the null hypothesis.
Know more about the binomial test
https://brainly.com/question/15278907
#SPJ11
calculate the line integral of the vector field along the line between the given points. f = x i y j , from (2, 0) to (8, 0)
Answers
The line integral of this vector which lies between the points. f = x i +y j , from (2, 0) to (8, 0) is 30.
To calculate the line integral of the vector field F(x, y) = xi + yj along the line between the points (2, 0) and (8, 0), we can parameterize the line segment and then evaluate the integral.
1. Parameterize the line segment:
Let r(t) = (1-t)(2, 0) + t(8, 0) for 0 ≤ t ≤ 1.
Then r(t) = (2 + 6t, 0).
2. Find the derivative of the parameterization:
r'(t) = (6, 0)
3. Evaluate the vector field F along the line segment:
F(r(t)) = (2 + 6t)i + (0)j
4. Take the dot product of F(r(t)) and r'(t):
F(r(t)) • r'(t) = (2 + 6t)(6) + (0)(0) = 12 + 36t
5. Integrate the dot product over the interval [0, 1]:
∫(12 + 36t) dt from 0 to 1 = [12t + 18t^2] evaluated from 0 to 1 = 12(1) + 18(1)^2 - 0 = 12 + 18 = 30
The line integral of the vector field along the line between the given points is 30.
Learn more about the line integral of the vector : https://brainly.com/question/31477889
#SPJ11
4. fsx, y, zd − tan21 sx 2 yz2 d i 1 x 2 y j 1 x 2 z2 k, s is the cone x − sy 2 1 z2 , 0 < x < 2, oriented in the direction of the positive x-axis
Answers
The direction of the positive x-axis is ∫∫S F · n dS
[tex]\int 0^2 \int 0^(1-u^2/4) -2u^3 \sqrt {v/(1+4v^2)} dv du+ \int 0^2 \int 0^(1-u^2/4) u^2 \sqrt {v/(1+4v^2)} dv du+ \int 0^2 \int 0^(1-u^2/4) u^2[/tex]
The surface integral need to parameterize the surface S of the cone and find the normal vector.
Then we can evaluate the dot product of the vector field F with the normal vector and integrate over the surface using the parameterization.
To parameterize the surface S can use the following parameterization:
r(x, y) = ⟨x, y, √(x² + y²)⟩ (x, y) is a point in the base of the cone.
The normal vector can take the cross product of the partial derivatives of r:
rₓ = ⟨1, 0, x/√(x² + y²)⟩
[tex]r_y[/tex] = ⟨0, 1, y/√(x² + y²)⟩
n(x, y) = [tex]r_x \times r_y[/tex]
= ⟨-x/√(x² + y²), -y/√(x² + y²), 1⟩
The direction of the normal vector to point outward from the cone, which is consistent with the orientation of the cone given in the problem.
To evaluate the surface integral need to compute the dot product of F with n and integrate over the surface S:
∫∫S F · n dS
Using the parameterization of S and the normal vector we found can write:
F · n = ⟨-tan(2xy²), x², x²⟩ · ⟨-x/√(x² + y²), -y/√(x² + y²), 1⟩
= -x³/√(x² + y²) tan(2xy²) - x² y/√(x² + y²) + x²
The trigonometric identity tan(2θ) = 2tan(θ)/(1-tan²(θ)):
F · n = -2x³ y/√(x² + y²) [1/(1+tan²(2xy²))] - x² y/√(x² + y²) + x²
To integrate over the surface S can use a change of variables to convert the double integral over the base of the cone to a double integral over a rectangular region in the xy-plane.
Letting u = x and v = y² the Jacobian of the transformation is:
∂(u,v)/∂(x,y) = det([1 0], [0 2y])
= 2y
The bounds of integration for the double integral over the base of the cone are 0 ≤ x ≤ 2 and 0 ≤ y ≤ √(1 - x²/4).
Substituting u = x and v = y² get the bounds 0 ≤ u ≤ 2 and 0 ≤ v ≤ 1 - u²/4.
For similar questions on direction
https://brainly.com/question/29248951
#SPJ11
If the perimeter of the entire shape is 25x+8, what is the expression for the missing side length
Answers
Work Shown:
m = length of the missing side
perimeter = add up the sides
perimeter = m+(4x)+(5x+2)+(5x-4)+(6x-8)
perimeter = m+20x-10
25x+8 = m+20x-10
25x+8-20x+10 = m
5x+18 = m
m = 5x+18
to test this series for convergence [infinity]
∑ n / √(n^5 + 6)
n=1
you could use the limit comparison test, comparing it to the series [infinity]
∑ 1 / n^p
n=1
where p= _____
completing the test, it shows the series:
a. diverges
b. converges
Answers
∑ [tex]1/n^2[/tex] b) converges, we can conclude that the given series also converges.Therefore, the answer is (b) converges.
To apply the limit comparison test, we need to choose a series that we already know converges or diverges, and then compare its limit with the limit of the given series.
Let's choose the series ∑ [tex]1/n^2[/tex]with p=2, which is a well-known convergent series. Then, we can take the limit as n approaches infinity of the ratio of the nth term of the given series to the nth term of the chosen series:
lim n→∞ (n/√[tex](n^5+6)) / (1/n^2)[/tex]
= lim n→∞ [tex](n^3[/tex] / √([tex]n^5[/tex]+6))
= lim n→∞ [tex](n^3 / n^(5/2))[/tex]
= lim n→∞ [tex](1 / n^{(1/2))[/tex]
= 0
Since the limit is finite and non-zero, we can conclude that the given series has the same convergence behavior as the series ∑[tex]1/n^2[/tex]. Since ∑ [tex]1/n^2[/tex] converges, we can conclude that the given series also converges.
Therefore, the answer is (b) converges.
for such more question on converges.
https://brainly.com/question/11354790
#SPJ11
∫c xy dx + (x + y)dy, where c is the boundary of the region lying between the graphs of x^2 + y^2=1 and x^2 + y^2=9 oriented in the counterclockwise direction
Answers
To evaluate the line integral ∫c (xy) dx + (x + y) dy, where c is the boundary of the region lying between the graphs of x^2 + y^2 = 1 and x^2 + y^2 = 9 oriented in the counterclockwise direction, we can parameterize the boundary curve and use the line integral formula.
The given line integral represents the circulation of the vector field F = (xy, x + y) around the boundary c of the region between the two circles x^2 + y^2 = 1 and x^2 + y^2 = 9.
To evaluate the line integral, we first need to parameterize the boundary curve c. One way to do this is to use polar coordinates. For the inner circle x^2 + y^2 = 1, we can parameterize it as x = cos(t), y = sin(t), where t ranges from 0 to 2π. For the outer circle x^2 + y^2 = 9, we can parameterize it as x = 3cos(t), y = 3sin(t), where t ranges from 0 to 2π.
Using these parameterizations, we can compute the line integral along each segment of the boundary curve. Since the curve is closed, the line integral along the complete curve will be the sum of the line integrals along each segment. We evaluate the line integral by substituting the parameterized values into the integrand and integrating with respect to the parameter.
After evaluating the line integrals along each segment of the boundary curve, we sum the results to obtain the final value of the line integral.
Note that the direction of integration is counterclockwise, which means that we need to ensure the orientation of each segment is consistent with this direction when evaluating the line integral
Learn more about vector field here:
https://brainly.com/question/102477
#SPJ11
1) Consider the relation R : → given by {(x, y) : sin2 x + cos2 x = y}. Determine whether R is a well-defined function.
2) Consider the relation R : → given by {(x, y) : y = tan x}. Determine whether R is a well-defined function.
3) Consider the relation R : → given by {(x, y) : xy = 1}. Determine whether R is a well-defined function.
There isn't any specific domain
Answers
A domain is the set of all possible input values for a function or relation. In these questions, the domain is not specified.
A relation is a set of ordered pairs that relates elements from two sets. In these questions, we are given relations defined by sets of ordered pairs.
To determine if a relation is a well-defined function, we need to check if each input has exactly one output. In other words, we need to check if there are no repeated inputs with different outputs.
1) The relation R given by {(x, y) : sin2 x + cos2 x = y} is a well-defined function because for every x in the domain, there is only one corresponding y. This is because sin2 x + cos2 x always equals 1, so there are no repeated inputs with different outputs.
2) The relation R given by {(x, y) : y = tan x} is not a well-defined function because there are multiple x values that correspond to the same y value. For example, tan(0) = 0 and tan(pi) = 0, so there are repeated inputs with the same output.
3) The relation R given by {(x, y) : xy = 1} is a well-defined function only if the domain excludes 0. This is because if x=0, then the relation is undefined. For all other values of x, there is only one corresponding y that makes the relation true.
To know more about domains visit:
https://brainly.com/question/26098895
#SPJ11
Is it possible for a nonhomogeneous system of seven equations in six unknowns to have a unique solution for some right-hand side of constants? Is it possible for such a system to have a unique solution for every right- hand side? Explain.
Answers
Yes, it is possible for a nonhomogeneous system of seven equations in six unknowns to have a unique solution for some right-hand side of constants.
This occurs when the right-hand side is chosen in such a way that the system of equations is consistent and the rank of the coefficient matrix is equal to six.
In this case, the unique solution can be found by using techniques such as Gaussian elimination or matrix inversion.
However, it is not possible for such a system to have a unique solution for every right-hand side. This is because if the rank of the coefficient matrix is less than six, then the system is underdetermined and there will be infinitely many solutions.
On the other hand, if the rank of the coefficient matrix is greater than six, then the system is overdetermined and there will be no solutions.
Therefore, a unique solution is only possible when the rank of the coefficient matrix is exactly six.
Know more about nonhomogeneous system here:
https://brainly.com/question/13720217
#SPJ11
use the ratio test to find the radius of convergence of the power series 4x 16x2 64x3 256x4 1024x5 ⋯ r=
Answers
The radius of convergence of the power series is R = 1/4.
To use the ratio test to find the radius of convergence of the power series [tex]4x + 16x^2 + 64x^3 + 256x^4 + 1024x^5 + ...,[/tex] you will follow these steps:
1. Identify the general term of the power series: [tex]a_n = 4^n * x^n.[/tex]
2. Calculate the ratio of consecutive terms:[tex]|a_{(n+1)}/a_n| = |(4^{(n+1)} * x^{(n+1)})/(4^n * x^n)|.[/tex]
3. Simplify the ratio:[tex]|(4 * 4^n * x)/(4^n)| = |4x|.[/tex]
4. Apply the ratio test: The power series converges if the limit as n approaches infinity of[tex]|a_{(n+1)}/a_n|[/tex]is less than 1.
5. Calculate the limit: lim (n->infinity) |4x| = |4x|.
6. Determine the radius of convergence: |4x| < 1.
7. Solve for x: |x| < 1/4.
Thus, using the ratio test, the radius of convergence of the given power series is r = 1/4.
To know more about radius of convergence refer here:
https://brainly.com/question/31789859
#SPJ11
What is the product of 76 and
6. 0
×
1
0
2
6. 0×10
2
expressed in scientific notation?
Answers
The product of 76 and 6.0 × 10² is 45,600, and when expressed in scientific notation, it is 4.56 × 10⁴.
To find the product of 76 and 6.0 × 10², we need to multiply these two numbers together. First, let's rewrite 6.0 × 10² in decimal form. In scientific notation, the number 6.0 × 10² means 6.0 multiplied by 10 raised to the power of 2.
10 raised to the power of 2 means multiplying 10 by itself twice: 10 × 10 = 100. Therefore, 6.0 × 10² can be rewritten as 6.0 × 100.
Now, we can find the product by multiplying 76 and 6.0 × 100:
76 × 6.0 × 100 = 456 × 100
To multiply 456 by 100, we move each digit of 456 two places to the left, which is equivalent to multiplying by 100. This gives us:
456 × 100 = 45,600
So, the product of 76 and 6.0 × 10² is 45,600.
In our case, the product is 45,600. To express this in scientific notation, we need to move the decimal point to the left until there is only one non-zero digit to the left of the decimal point. In this case, we move the decimal point four places to the left:
45,600 = 4.56 × 10⁴
Therefore, the product of 76 and 6.0 × 10² expressed in scientific notation is 4.56 × 10⁴.
To know more about Scientific notation here
https://brainly.com/question/19625319
#SPJ4
determine the coordinates of the center of this circle x^2 2x y^2-4y=12
Answers
The coordinates of the center of the circle x^2 + 2x + y^2 - 4y = 12 are (-1, 2).
To determine the coordinates of the center of the circle defined by the equation x^2 + 2x + y^2 - 4y = 12, we need to complete the square for both the x and y terms.
Starting with the x terms, we can add (2/2)^2 = 1 to both sides of the equation to get:
x^2 + 2x + 1 + y^2 - 4y = 12 + 1
Simplifying:
(x + 1)^2 + (y - 2)^2 = 13
Comparing this to the standard form of a circle, (x - h)^2 + (y - k)^2 = r^2, we see that the center of the circle is (-1, 2) and the radius is sqrt(13).
Therefore, the coordinates of the center of the circle x^2 + 2x + y^2 - 4y = 12 are (-1, 2).
Learn more about circle here
https://brainly.com/question/28162977
#SPJ11
An SRS of 16 items is taken from Population 1 and yields an average = 253 and standard deviation s1 = 32. An SRS of 20 items is taken (independently of the first sample) from Population 2 and yields an average = 248 and a standard deviation s2 = 36. Assuming the two populations have the same variance σ2 and the pooled variance estimator of σ2 is used, the standard error of is:
Answers
The standard error of the difference between the means is 8.45.
The standard error is a measure of the variability of a sample statistic, such as the mean, compared to the population parameter it estimates.
In this case, we are interested in the standard error of the difference between the means of two independent samples, which is calculated using the pooled variance estimator assuming equal population variances. The formula for the standard error of the difference between two sample means is:
SE = √[ (s1^2/n1) + (s2^2/n2) ]
Where s1 and s2 are the standard deviations of the two samples, n1 and n2 are the sample sizes, and SE is the standard error of the difference between the sample means. Substituting the given values, we get:
SE = √[ (32^2/16) + (36^2/20) ] = 8.45
This means that if we were to take repeated random samples from the same population using the same sample sizes, the standard deviation of the sampling distribution of the difference between the means would be approximately 8.45.
To learn more about : error
https://brainly.com/question/28771966
#SPJ11
The standard error of the pooled sample means is approximately 7.15.
The standard error of the pooled sample means is calculated using the formula:
Standard Error = √[(s1^2 / n1) + (s2^2 / n2)]
Where s1 and s2 are the standard deviations of the two samples, n1 and n2 are the sizes of the samples.
In this case, s1 = 32, s2 = 36, n1 = 16, and n2 = 20. Substituting these values into the formula, we have:
Standard Error = √[(32^2 / 16) + (36^2 / 20)]
Standard Error = √[1024 / 16 + 1296 / 20]
Standard Error = √[64 + 64.8]
Standard Error = √128.8
Standard Error ≈ 7.15
Therefore, the standard error of the pooled sample means is approximately 7.15. The standard error represents the variability or uncertainty in estimating the population means based on the sample means. A smaller standard error indicates a more precise estimation of the population means, while a larger standard error indicates more variability and less precise estimation.
Visit here to learn more about standard error :
brainly.com/question/13179711
#SPJ11
T/F Symmetric Confidence intervals are used to draw conclusions about two-sided hypothesis tests.
Answers
True. Symmetric Confidence intervals are used to draw conclusions about two-sided hypothesis tests.
Confidence intervals are used to estimate the range of plausible values for a population parameter (e.g., mean, proportion) based on a sample.
Symmetric confidence intervals assume that the distribution of the population parameter is symmetric and can be approximated by a normal distribution.
When we use a two-sided hypothesis test, we test whether the population parameter is different from a hypothesized value, so we need to estimate both the lower and upper bounds of the plausible range of values.
This is where symmetric confidence intervals are useful. They provide a range of values symmetrically around the point estimate, which can be used to draw conclusions about a two-sided hypothesis test.
Know more about Confidence intervals here:
https://brainly.com/question/20309162
#SPJ11
Suppose that a particle moves along a straight line with velocity defined by v(t)=t 2
−2t−24, where 0≤t≤6 (in meters per second). Find the displacement (in meters) at time t. d(t)= Find the total distance traveled (in meters) up to t=6. m
Answers
The total distance traveled up to t=6 can be obtained by integrating the absolute value of the velocity function over the interval [0, 6].
To find the displacement at time t, we need to integrate the velocity function, v(t), with respect to t. The displacement function, d(t), is the antiderivative of v(t). Integrating v(t) with respect to t, we get:
d(t) = ∫[tex](t^2 - 2t - 24)[/tex] dt
Evaluating the integral, we obtain:
[tex]d(t) = (1/3)t^3 - t^2 - 24t + C[/tex]
where C is the constant of integration. Since we are interested in the displacement at time t, we can find the specific value of C by evaluating d(t) at a known time, such as t=0. Substituting t=0 into the equation and assuming the particle starts at the origin, we have:
[tex]0 = (1/3)(0)^3 - (0)^2 - 24(0) + C[/tex]
0 = C
Therefore, the displacement function becomes:
[tex]d(t) = (1/3)t^3 - t^2 - 24t[/tex]
To find the total distance traveled up to t=6, we need to integrate the absolute value of the velocity function over the interval [0, 6]. The total distance, D(t), is given by:
D(t) = ∫|v(t)| dt
Substituting the given velocity function, we have:
D(t) = ∫[tex]|t^2 - 2t - 24| dt[/tex]
Integrating the absolute value function involves breaking the integral into different intervals based on the sign of the integrand. In this case, we have two intervals: [0, 4] and [4, 6]. Integrating over these intervals separately and taking the absolute values of the results, we can find the total distance traveled up to t=6.
Learn more about antiderivative here: https://brainly.com/question/31396969
#SPJ11
Following is information on the price per share and the dividend for a sample of 30 companies.Company Price Per Share Devidend1 $20.11 $3.142 22.12 3.36. . .. . .. . .39 78.02 17.6540 80.11 17.36a. Calculate the regression equation that predicts price per share based on the annual dividend. (Round your answers to 4 decimal places.) b-2. State the decision rule. Use the 0.05 significance level. (Round your answer to 3 decimal places.) b-3. Compute the value of the test statistic. (Round your answer to 4 decimal places.) c. Determine the coefficient of determination. (Round your answer to 4 decimal places.) d-1. Determine the correlation coefficient. (Round your answer to 4 decimal places.) e. If the dividend is $10, what is the predicted price per share? (Round your answer to 4 decimal places.) f. What is the 95% prediction interval of price per share if the dividend is $10? (Round your answers to 4 decimal places.)
Answers
Company Price Per Share Devidend
a. The regression equation is: y = 24.659 + 1.8435x
b-2. H0 is the null hypothesis (b1 = 0), t is the test statistic, and tc is the critical value from the t-distribution with n-2 degrees of freedom.
b-3. The t-statistic: t = (b1 - 0)/SEb1 = 7.7083
c. R² = 0.3703
d-1. The correlation coefficient is 0.9873.
e. The predicted price per share for a dividend of [tex]$10[/tex] is [tex]$8.1189[/tex].
f. The 95% prediction interval of price per share for a dividend of [tex]$10[/tex] is [tex]($7.1059, $9.1319)[/tex].
The regression equation that predicts price per share based on the annual dividend, we need to perform a linear regression analysis.
Using a statistical software or calculator, we obtain the following regression equation:
Price per share = -30.0145 + 2.1132 × Dividend
The regression equation that predicts price per share based on the annual dividend is:
Price per share = -30.0145 + 2.1132 × Dividend
The decision rule for testing the significance of the regression slope coefficient at the 0.05 significance level is:
Reject the null hypothesis if the p-value is less than 0.05.
To compute the value of the test statistic, we need to perform a hypothesis test on the slope coefficient using the regression output.
The null hypothesis is that the slope coefficient is zero, and the alternative hypothesis is that the slope coefficient is not zero.
Using the regression output, we obtain the following results:
Slope coefficient (b1) = 2.1132
Standard error (SE) = 0.1988
Degrees of freedom (df) = 28
t-statistic = b1 / SE = 2.1132 / 0.1988 = 10.6178
p-value = P(|t| > 10.6178) < 0.0001
The value of the test statistic is 10.6178.
The coefficient of determination, denoted by R², measures the proportion of variation in the dependent variable (price per share) that is explained by the independent variable (dividend).
Using the regression output, we obtain R² = 0.9748.
The coefficient of determination is 0.9748.
The correlation coefficient, denoted by r, measures the strength and direction of the linear relationship between the two variables.
Using the regression output, we obtain r = 0.9873.
The correlation coefficient is 0.9873.
To predict the price per share for a dividend of [tex]$10[/tex], we plug in the value of 10 for Dividend in the regression equation:
Price per share = -30.0145 + 2.1132 × 10 = [tex]$8.1189[/tex]
The predicted price per share for a dividend of [tex]$10[/tex] is [tex]$8.1189[/tex].
The 95% prediction interval of price per share for a dividend of [tex]$10[/tex], we use the following formula:
y = b0 + b1x ± tα/2, n-2 × SE (y -hat)
where y-hat is the predicted value of price per share for a dividend of $10, SE (y -hat) is the standard error of the estimate, n is the sample size, and tα/2, n-2 is the t-value from the t-distribution with n-2 degrees of freedom and a significance level of α/2 = 0.025. Using the regression output, we obtain:
y-hat = -30.0145 + 2.1132 × 10 = [tex]$8.1189[/tex]
SE(y -hat) = 0.5079
n = 30
tα/2, n-2 = 2.0452 (from the t-distribution table)
Substituting these values, we obtain:
95% prediction interval =[tex]$8.1189 \pm 2.0452 \times 0.5079[/tex] = [tex]($7.1059, $9.1319)[/tex]
For similar questions on Devidend
https://brainly.com/question/2960815
#SPJ11
a. The regression equation that predicts price per share based on the annual dividend is: Price per share = -2.8991 + 0.6761 * Dividend.
b-2. The decision rule states that if the absolute value of the test statistic is greater than the critical value, we reject the null hypothesis. b-3. The value of the test statistic is 4.6053. c. The coefficient of determination (R-squared) is 0.5063.
d-1. The correlation coefficient is 0.7113. e. If the dividend is $10, the predicted price per share is $13.8629. f. The 95% prediction interval of price per share, given a dividend of $10, is approximately $9.2236 to $18.5023.
To calculate these values, linear regression is performed on the given data. The regression equation is obtained, indicating the relationship between price per share and the annual dividend.
The decision rule is based on the significance level, determining the critical value for hypothesis testing. The test statistic is calculated to assess the significance of the regression coefficient. The coefficient of determination measures the proportion of the variation in price per share explained by the dividend.
The correlation coefficient quantifies the strength and direction of the linear relationship. Finally, using the regression equation, the predicted price per share for a given dividend value and the prediction interval are determined.
To learn more about regression equation click here
brainly.com/question/30742796
#SPJ11
Please see if you know this
Answers
Answer:
A. 0.5, 5/8, 1 5/10, 1.58.
Answer: prob a
Step-by-step explanation:
Let A = and b The QR factorization of the matrix A is given by: 3 3 2 V }V2 3 4 Applying the QR factorization to solving the least squares problem Ax = b gives the system: 9]-[8] (b) Use backsubstitution to solve the system in part (a) and find the least squares solution_
Answers
Let A be a given matrix and b be a given vector. The QR factorization of the matrix A involves finding two matrices Q and R, where Q is orthogonal and R is upper-triangular.
To solve the least squares problem Ax = b using QR factorization, we first find the QR factorization of A:
A = QR
Next, we express the problem as:
QRx = b
Now, we can multiply both sides by the transpose of Q (since Q is orthogonal, its transpose is its inverse):
(Q^T)QRx = (Q^T)b
This simplifies to:
Rx = (Q^T)b
Since R is an upper-triangular matrix, we can use back-substitution to solve the system Rx = (Q^T)b and find the least squares solution.
1. Compute the matrix product (Q^T)b.
2. Use back-substitution to solve the upper-triangular system Rx = (Q^T)b, starting with the last equation and working upward.
The solution x obtained through this process is the least squares solution for Ax = b.
To know more about QR factorization refer here:
https://brainly.com/question/30481086?#
#SPJ11
solve the following problem n = 20; i = 0.046; pmt = $188; pv = ?
Answers
The present value (PV) can be calculated using the formula PV = pmt * (1 - (1 + i)^(-n)) / i.
The problem provides the following information:
n = 20: The number of periods or the total number of payments.i = 0.046: The interest rate per period.pmt = $188: The payment made at each period.To find the present value (PV), we can use the formula mentioned above. The formula calculates the discounted value of a series of future cash flows by considering the interest rate and the number of periods.
Using the provided values, we can substitute them into the formula:
PV = pmt * (1 - (1 + i)^(-n)) / i
= $188 * (1 - (1 + 0.046)^(-20)) / 0.046
Evaluating the expression inside the parentheses first:
(1 + 0.046)^(-20) ≈ 0.5683
Substituting this value back into the equation:
PV = $188 * (1 - 0.5683) / 0.046
= $188 * 0.4317 / 0.046
≈ $1752.87
Therefore, the present value (PV) is approximately $1752.87.
The present value represents the current worth of a series of future cash flows, taking into account the time value of money. In this context, it indicates the amount of money that, if invested at the given interest rate, would generate the same series of cash flows as the payments over the specified number of periods.
This calculation is commonly used in finance, investment analysis, and loan amortization to determine the value of future cash flows in today's dollars. It helps in evaluating the profitability of investments, determining loan amounts, and making financial decisions based on the time value of money.
To learn more about present value, click here: brainly.com/question/14962478
#SPJ11
a storage shed is to be built in the shape of a box with a square base. it is to have a volume of 729 cubic feet. the concrete for the base costs $5 per square foot, the material for the roof costs $6 per square foot, and the material for the sides costs $5.50 per square foot. find the dimensions of the most economical shed.
Answers
There is no minimum value for the side length x, and thus it is not possible to determine the dimensions of the most economical shed.
To find the dimensions of the most economical shed, we need to consider the cost of each component (base, roof, and sides) based on the given cost per square foot. Let's denote the side length of the square base as x.
The volume of the shed is given as 729 cubic feet, and since the base is square, the height of the shed is also x.
The cost of the base would be the area of the base (x * x) multiplied by the cost per square foot, which is 5 * x².
The cost of the roof would be the area of the base (x * x) multiplied by the cost per square foot, which is 6 * x².
The cost of the sides would be the sum of the areas of all four sides (2 * x * x) multiplied by the cost per square foot, which is 4 * 5.5 * x².
To find the most economical shed, we need to minimize the total cost, which is the sum of the costs of the base, roof, and sides.
Total Cost = Cost of Base + Cost of Roof + Cost of Sides
= 5 * x² + 6 * x² + 4 * 5.5 * x²
= 11 * x² + 22 * x²
= 33 * x²
To minimize the total cost, we need to minimize x², which means finding the minimum value of x.
Taking the derivative of the total cost function with respect to x and setting it to zero, we can find the critical points:
d(Total Cost)/dx = 66 * x = 0
From this, we can see that x = 0 is not a valid solution. Therefore, we can divide both sides by 66 to find:
x = 0
Since the side length cannot be zero, we can conclude that the minimum value of x is not achievable.
Hence, there is no minimum value for the side length x, and thus we cannot determine the dimensions of the most economical shed based on the given volume and cost information.
Learn more about volume here:
https://brainly.com/question/28058531
#SPJ11
let s be the hemisphere x2 y2 z2 = 4 with z ≥0. evaluate∫ ∫ s (x2 y2)z ds
Answers
The final result is:
∫∫s (x²y²)z ds = -32(2/15) = -64/15.
To evaluate the given surface integral, we can use the parametrization of the hemisphere in spherical coordinates as follows:
x = 2sinθcosφ
y = 2sinθsinφ
z = 2cosθ
where 0 ≤ θ ≤ π/2 and 0 ≤ φ ≤ 2π.
Using the Jacobian transformation, we have
∂(x,y,z)/∂(θ,φ) = 4sinθ
and the surface element can be expressed as
ds = √(dx²+dy²+dz²) = 2sinθ√(1+cos²θ)dθdφ
Then, the integral can be written as:
∫∫s (x²y²)z ds = ∫₀^(2π) ∫₀^(π/2) (2sinθcosφ)²(2cosθ)²(2sinθ√(1+cos²θ)) dθdφ
Simplifying this expression, we have:
∫∫s (x²y²)z ds = 32∫₀^(2π) ∫₀^(π/2) sin⁵θcos³φdθdφ
Using the identity sin⁵θ = (1-cos²θ)²sinθ, we can rewrite the integral as:
∫∫s (x²y²)z ds = 32∫₀^(2π) ∫₀^(π/2) (1-cos²θ)²sin²θcos³φdθdφ
Then, using the substitution u = cosθ, du = -sinθ dθ, we have:
∫∫s (x²y²)z ds = -32∫₁⁰ (1-u²)²u²du ∫₀^(2π) cos³φdφ
Integrating the second integral, we get:
∫₀^(2π) cos³φdφ = 0
since the integrand is an odd function.
For the first integral, we can expand the polynomial and use the power rule:
∫₁⁰ (1-u²)²u²du = ∫₁⁰ u² - 2u⁴ + u⁶ du = [u³/3 - 2u⁵/5 + u⁷/7]₁⁰ = 2/15
Therefore, the final result is:
∫∫s (x²y²)z ds = -32(2/15) = -64/15.
To know more about Jacobian transformation refer here:
https://brainly.com/question/9381576
#SPJ11
describe the total variation about a regression line in words and symbols.
Answers
Total variation about a regression line, also known as total sum of squares (SST), is a measure of how much the data points deviate from the regression line.
It is represented by the formula SST = Σ(y - ȳ)², where y is the observed value, ȳ is the mean value, and Σ represents the sum of all values.
SST is a combination of two other measures: explained variation (SSE), which measures how much of the variation is explained by the regression line, and residual variation (SSR), which measures the unexplained variation.
SST can be decomposed into these two measures using the formula SST = SSE + SSR.
In other words, SST represents the total amount of variation in the data, both explained and unexplained, around the regression line.
Learn more about regression line at
https://brainly.com/question/7656407
#SPJ11
compute the surface area of revolution of y=4x 3y=4x 3 about the x-axis over the interval [4,5][4,5].
Answers
The surface area of revolution of y = 4[tex]x^3[/tex] about the x-axis over the interval [4, 5] is approximately 806.259 square units.
To find the surface area of revolution of the curve y = 4[tex]x^3[/tex] about the x-axis over the interval [4, 5], we can use the formula:
S = 2π ∫ [a,b] y √(1 + [tex](dy/dx)^2[/tex]) dx
where a = 4, b = 5, and dy/dx = 12[tex]x^2[/tex].
Substituting these values, we get:
S = 2π ∫[4,5] 4x [tex]\sqrt{(1 + (12x^2)^2)}[/tex] dx
Simplifying the expression inside the square root:
1 + [tex](12x^2)^2[/tex] = 1 + 144[tex]x^4[/tex]
= 144[tex]x^4[/tex] + 1
The integral becomes:
S = 2π ∫[4,5] 4x √(144[tex]x^4[/tex] + 1) dx
To evaluate this integral, we can make the substitution u = 144[tex]x^4[/tex] + 1. Then, du/dx = 576[tex]x^3[/tex], and dx = du/576[tex]x^3[/tex].
Substituting these values, we get:
S = 2π ∫[577, 11521] 4x √u du / (576x^3)
Simplifying:
S = π/36 ∫[577, 11521] √u du
S = π/36 x (2/3) x [tex](11521^{(3/2)} - 577^{(3/2)})[/tex]
S = π/54 x [tex](11521^{(3/2)} - 577^{(3/2)})[/tex]
Using a calculator, we can approximate this value to be:
S ≈ 806.259
For similar question on surface area
https://brainly.com/question/26403859
#SPJ11
According to Newton's law of cooling (sec Problem 23 of Section 1.1), the temperature u(t) of an object satisfies the differential equation du/dt = -K(u - T) where T is the constant ambient temperature and k is a positive constant. Suppose that the initial temperature of the object is u(0) = u_0 Find the temperature of the object at any time.
Answers
Newton's law of cooling describes how the temperature of an object changes over time in response to the surrounding temperature. The equation that governs this process is du/dt = -K(u - T), where u is the temperature of the object at any given time, T is the constant ambient temperature, and K is a positive constant.
To find the temperature of the object at any time, we need to solve this differential equation. First, we can separate the variables by dividing both sides by (u-T), which gives us du/(u-T) = -K dt. Integrating both sides, we get ln|u-T| = -Kt + C, where C is a constant of integration. Exponentiating both sides, we get u-T = e^(-Kt+C), or u(t) = T + Ce^(-Kt).
To find the value of the constant C, we use the initial condition u(0) = u_0. Plugging in t=0 and u(0) = u_0 into the equation above, we get u_0 = T + C. Solving for C, we get C = u_0 - T. Substituting this value of C into the equation for u(t), we get u(t) = T + (u_0 - T)e^(-Kt).
Therefore, the temperature of the object at any time t is given by u(t) = T + (u_0 - T)e^(-Kt).
According to Newton's law of cooling, the temperature u(t) of an object can be determined using the differential equation du/dt = -K(u - T), where T is the constant ambient temperature, and K is a positive constant. To find the temperature of the object at any time, given the initial temperature u(0) = u_0, we need to solve this differential equation.
Step 1: Separate the variables by dividing both sides by (u - T) and multiplying both sides by dt:
(1/(u - T)) du = -K dt
Step 2: Integrate both sides with respect to their respective variables:
∫(1/(u - T)) du = ∫-K dt
Step 3: Evaluate the integrals:
ln|u - T| = -Kt + C, where C is the constant of integration.
Step 4: Take the exponent of both sides to eliminate the natural logarithm:
u - T = e^(-Kt + C)
Step 5: Rearrange the equation to isolate u:
u(t) = T + e^(-Kt + C)
Step 6: Use the initial condition u(0) = u_0 to find the constant C:
u_0 = T + e^(C), so e^C = u_0 - T
Step 7: Substitute the value of e^C back into the equation for u(t):
u(t) = T + (u_0 - T)e^(-Kt)
This equation gives the temperature of the object at any time t, taking into account Newton's law of cooling, the ambient temperature T, and the initial temperature u_0.
For more information on Newton's law visit:
brainly.com/question/15280051
#SPJ11
Thus, the equation that gives the temperature of the object at any time t, considering the initial temperature u_0 and the ambient temperature T is u(t) = T + (u_0 - T)e^(-Kt).
According to Newton's law of cooling, the temperature u(t) of an object satisfies the differential equation du/dt = -K(u - T), where T is the constant ambient temperature and K is a positive constant.
Given the initial temperature u(0) = u_0, we can solve this differential equation to find the temperature of the object at any time.
To solve the differential equation, we can use separation of variables:
1/(u - T) du = -K dt
Integrate both sides:
∫(1/(u - T)) du = ∫(-K) dt
ln|u - T| = -Kt + C (where C is the integration constant)
Now, we can solve for u(t):
u - T = Ce^(-Kt)
To find the constant C, we use the initial condition u(0) = u_0:
u_0 - T = Ce^(-K*0)
u_0 - T = C
So, our temperature function is:
u(t) = T + (u_0 - T)e^(-Kt)
This equation gives the temperature of the object at any time t, considering the initial temperature u_0 and the ambient temperature T.
Know more about the Newton's law of cooling
https://brainly.com/question/2763155
#SPJ11
Expand the function 13+4x13+4x in a power series ∑=0[infinity]x∑n=0[infinity]anxn with center c=0.center c=0. Find x.anxn.
(Express numbers in exact form. Use symbolic notation and fractions where needed. For alternating series, include a factor of the form (−1)(−1)n in your answer.)
x=anxn=
Determine the interval of convergence.
(Give your answers as intervals in the form (∗,∗).(∗,∗). Use symbol [infinity][infinity] for infinity, ∪∪ for combining intervals, and appropriate type of parenthesis "(",")", "["or"]""(",")", "["or"]" depending on whether the interval is open or closed. Enter DNEDNE if interval is empty. Express numbers in exact form. Use symbolic notation and fractions where needed.)
x∈x∈
Answers
The expansion of the function is 13 - 52/169 x + 416/2197 x^2 - 3328/28561 x^3 + 26624/371293 x^4 - ... and the interval of convergence is (-17/4, -13/4).
To expand the function 13+4x13+4x in a power series ∑=0[infinity]x∑n=0[infinity]anxn with center c=0, we can use the formula:
∑n=0[infinity]an(x-c)^n
where c is the center of the power series, and an can be found using the formula:
an = f^(n)(c)/n!
where f^(n) denotes the nth derivative of the function.
In this case, we have:
f(x) = 13 + 4x / (13 + 4x)
Taking derivatives, we get:
f'(x) = -52 / (13 + 4x)^2
f''(x) = 416 / (13 + 4x)^3
f'''(x) = -3328 / (13 + 4x)^4
f''''(x) = 26624 / (13 + 4x)^5
...
Evaluating these derivatives at x=0, we get:
f(0) = 13
f'(0) = -52/169
f''(0) = 416/2197
f'''(0) = -3328/28561
f''''(0) = 26624/371293
...
Therefore, the power series expansion of f(x) about x=0 is:
13 - 52/169 x + 416/2197 x^2 - 3328/28561 x^3 + 26624/371293 x^4 - ...
To determine the interval of convergence, we can use the ratio test:
lim |an+1(x-c)^(n+1)/an(x-c)^n| = lim |(13 + 4x)/(17 + 4x)| < 1
x → 0
Solving for x, we get:
-17/4 < x < -13/4
Therefore, the interval of convergence is (-17/4, -13/4).
Know more about convergence here:
https://brainly.com/question/30275628
#SPJ11
the effect estimate derivedfrom a cox proportional hazards model is: (select the best asnwer)
a. The model assesses the effect of the predictor variables on the hazard function
b. The regression equation is the product of the baseline hazard function and an exponentiated linear function of a set of predictor variables
c. The model makes no assumption regarding the shape of the hazard function
d. The baseline hazard function must be estimated to derive valid parameter estimates for the predictor variables
Answers
The correct answer is b. The effect estimate derived from a Cox proportional hazards model is the product of the baseline hazard function and an exponentiated linear function of a set of predictor variables.
The Cox proportional hazards model is a commonly used statistical method in survival analysis, which is used to analyze time-to-event data.
The model is based on the assumption that the hazard function (i.e., the probability of an event occurring at a given time) is proportional to the baseline hazard function multiplied by a function of the predictor variables.
One of the advantages of the Cox proportional hazards model is that it makes no assumption about the shape of the hazard function, which can be useful when analyzing data that do not follow a specific distribution.
Instead, the model focuses on estimating the effect of the predictor variables on the hazard function, which can provide insights into the factors that influence the risk of an event occurring.
In order to derive valid parameter estimates for the predictor variables, the baseline hazard function must be estimated. This can be done using various methods, such as the Breslow method or the Efron method.
Once the baseline hazard function is estimated, the effect of the predictor variables can be calculated using the exponentiated coefficients from the Cox proportional hazards model.
Overall,
The Cox proportional hazards model is a powerful tool for analyzing time-to-event data and can provide valuable insights into the factors that influence the risk of an event occurring.
By taking into account both the baseline hazard function and the effect of predictor variables, the model can provide a comprehensive understanding of the relationship between different factors and the risk of an event occurring.
For similar question on linear function :
https://brainly.com/question/20286983
#SPJ11
The effect estimate derived from a Cox proportional hazards model is an important tool for predicting the likelihood of an event occurring over time. However, to ensure that the parameter estimates for predictor variables are valid, it is necessary to estimate the baseline hazard function.
This is because the Cox model assumes that the hazard function is proportional over time, which is necessary for regression analysis. If this assumption is not met, the model may produce biased estimates. Estimating the baseline hazard function allows for the adjustment of the effect estimates for predictor variables, which helps to produce more accurate results. Therefore, it is crucial to carefully consider this assumption when using a Cox proportional hazards model.
The effect estimate derived from a Cox Proportional Hazards Model is indeed related to the statement: The baseline hazard function must be estimated to derive valid parameter estimates for the predictor variables.
The Cox Proportional Hazards Model is a regression model used to analyze survival data by examining the relationship between predictor variables and the hazard rate. The equation for this model includes a baseline hazard function and a set of predictor variables. An important assumption of the model is that the hazard ratios for the predictor variables are constant over time, meaning the effect of predictor variables on the hazard rate is proportional.
In order to obtain valid parameter estimates for the predictor variables, the baseline hazard function must be estimated accurately. This ensures that the effect estimates from the Cox Proportional Hazards Model are reliable and reflect the true relationship between the predictor variables and the hazard rate.
To learn more about Regression: brainly.com/question/28178214
#SPJ11
verify the approximation using technology. (use decimal notation. give your answer to four decimal places.) 0.005,42=
Answers
Verifying the approximation,0.005,42 ≈ 0.0054
Is the approximation of 0.005,42 approximately 0.0054?The given question requires verification of the approximation 0.005,42, expressed in decimal notation and rounded to four decimal places. By evaluating the given number, we can approximate it as 0.0054.
In the approximation process, we focus on the digit immediately after the decimal point. If it is less than 5, we drop it, and if it is 5 or greater, we round up the preceding digit. In this case, the digit after the decimal point is 4, which is less than 5. Therefore, we drop it, resulting in the approximation of 0.005,42 as 0.0054.
By following the rounding rules for decimal approximation, we can verify that the approximate value of 0.005,42 is indeed 0.0054.
Learn more about decimal approximation
brainly.com/question/30591123
#SPJ11
find the smallest n such that the error estimate in the approximation of the definite integral f6/0 √6 x dx is less than 0.00001 using simpson's rule.
Answers
Definite integral ∫(0 to √6) f(x) dx using Simpson's rule is less than 0.00001, we need to calculate the error formula for Simpson's rule and iterate over different values of n until the error estimate satisfies the given condition.
Simpson's rule is a numerical method used for approximating definite integrals. The error estimate for Simpson's rule is given by the formula:
[tex]E = -((b - a)^5 / (180 * n^4)) * f''(c)[/tex]
Where E represents the error estimate, (b - a) is the interval length (in this case, √6 - 0 = √6), n is the number of subintervals, f''(c) is the second derivative of the function evaluated at a point c within the interval.
To find the smallest n for which the error estimate is less than 0.00001, we can start by choosing an arbitrary value of n, calculating the error estimate using the given formula, and then checking if it is smaller than the desired tolerance. If it is not, we increase the value of n and recalculate the error estimate until it meets the condition.
By iteratively increasing the value of n and calculating the error estimate, we can determine the smallest value of n for which the error estimate in the approximation of the definite integral satisfies the condition of being less than 0.00001.
Learn more about derivative here: https://brainly.com/question/29020856
#SPJ11
Select all of the options that correspond to possible bootstrap samples from the following sample values: -8, -3, 13, 2, 15 -3,-8, 13, 2, 2 0 -3, 13, -8, -8,-3, 31, 14, -2 -8, -8, -8,-8, -8 15, 2, 15, 2, -3
Answers
The possible bootstrap samples from the given sample values are:
-3,-8,13,2,2
0,-3,13,-8,-8,-3,31,14,-2
-8,-8,-8,-8,-8
15,2,15,2,-3
What are the possible bootstrap samples from the given sample values?Bootstrap sampling is a statistical technique for estimating the sampling distribution of an estimator by sampling with replacement from the original sample data. The possible bootstrap samples from the given sample values can be obtained by randomly selecting samples of the same size as the original sample, with replacement.
The selected values are then used to form the bootstrap sample. The number of possible bootstrap samples is very large and depends on the size of the original sample.
In this case, we are given a sample of size 5 with values -8, -3, 13, 2, 15. To obtain the possible bootstrap samples, we can randomly select 5 values from this sample with replacement. One possible bootstrap sample is -3,-8,13,2,2. Similarly, we can repeat this process to obtain other possible bootstrap samples, which are 0,-3,13,-8,-8,-3,31,14,-2, -8,-8,-8,-8,-8, and 15,2,15,2,-3.
Learn more about Bootstrap sampling
brainly.com/question/31629604
#SPJ11